Reduce TTFT by >50% with LMCache + Momento
In this series, we investigate the performance gains for large-scale inference clusters with distributed KV caching, optimized routing, cluster orchestration, and other techniques. This post focuses on offloading the KV cache to remote storage (Valkey + S3) with LMCache and Momento Accelerator.
Momento specializes in hyperscale caching and routing, managing some of the largest Valkey / Redis clusters in the world for companies like Snap, Coinbase, Paramount, and Capcom. Momento Accelerator for AI (MAX AI) is a collection of high-performance components that integrate with common frameworks like vllm and sglang.
KV cache eviction erodes GPU performance
Typical inference scenarios fill large portions of the context window across each request with identical content, whether system prompts, data fragments, or short-term history. Reprocessing that data is a constant tax on your inference cluster, burning precious GPU cycles on unnecessary, redundant work.
Of course, when a follow-up request hits the same GPU, it is able to leverage the existing cache in high-bandwidth memory (HBM) to avoid much of the prefill stage. State of the art solutions for KV cache offloading focus on extending HBM with local storage (DRAM / NVMe) on inference workers.
However, local caches are ultimately too inflexible to avoid eviction and wasteful re-computation, especially at scale.
How does distributed KV cache offloading work?
Distributed cache offloading instead leverages a specialized token store designed for fast access to vast quantities of data, so you never discard previous work.
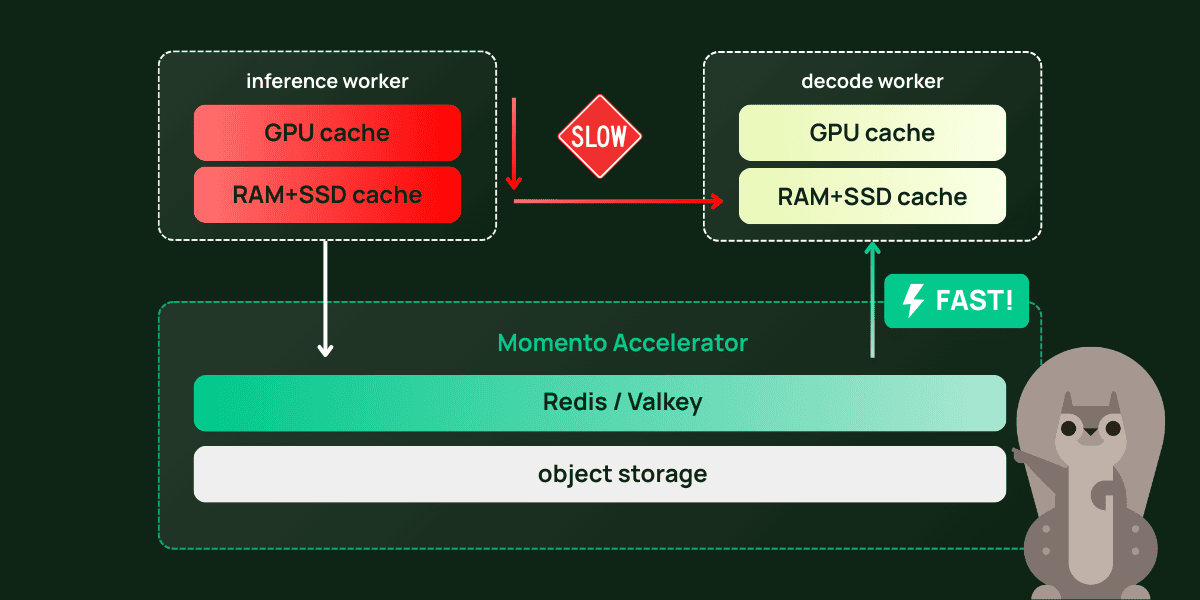
Distributed KV cache offloading extends limited GPU memory with unified access to multiple tiers of local and remote storage, connecting peer inference workers and dedicated storage nodes via a high-bandwidth transfer engine. This delivers PBs of cheap, durable storage that can rehydrate an inference worker’s KV cache in less time than it takes to recompute the same data.
Momento Accelerator for S3 (MAX S3) is a low-latency object store that layers Valkey in front of S3, perfect for a high-performance token store. MAX S3 handles production workloads with Tbps throughput for petabytes of data at sub-millisecond latency, for diverse use cases such as live-streaming video, multiplayer gaming, IoT analytics, and web-scale consumer apps.
Reducing Cold-Start Latency with LMCache + Momento Accelerator
For this benchmark, we evaluate cache performance with standard open-source components vLLM and LMCache, plus Momento Accelerator.
The benchmark rotates through a set of unique long contexts, which resembles common multi-tenant workloads like multi-turn conversations and enterprise RAG. During a warmup phase, each context is submitted once to seed the distributed cache. Then, the local cache is cleared and each context is submitted again to measure cold start TTFT.
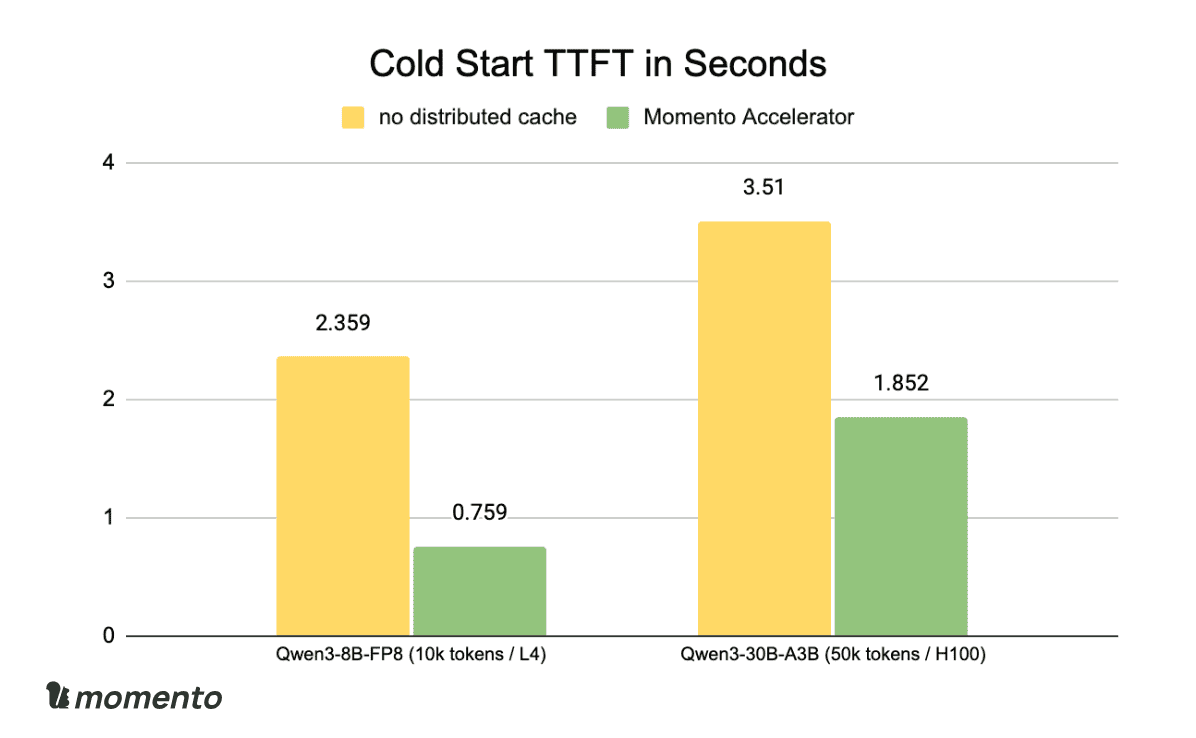
The persistent distributed cache reduces cold start TTFT by >50%, which is an excellent win. The ability to rapidly warm up new nodes from cheap, durable storage is foundational for more efficient, proactive cluster management.
Up Next
The Momento Accelerator integration with LMCache and vLLM is the result of a quick 1-week investigation. Stay tuned as we evaluate more improvements over the coming days!
We've identified many opportunities to optimize high-level components of LMCache and vLLM in Rust, leveraging our expertise with ultra-low-latency distributed systems. In particular, we expect router and control plane integrations to enable proactive cluster management with cache prefetching and load-aware scheduling.
Deploying Valkey + S3 as a Token Store with Momento Accelerator
Momento Accelerator for S3 is a tiered object store that makes it easy to deploy low-latency, durable storage. We have built a custom high-bandwidth connector for vLLM + LMCache that leverages our experience in hyperscale caching. As the connector is currently under rapid development / iteration, please contact us if you want help with benchmarking your production use case!